histograph
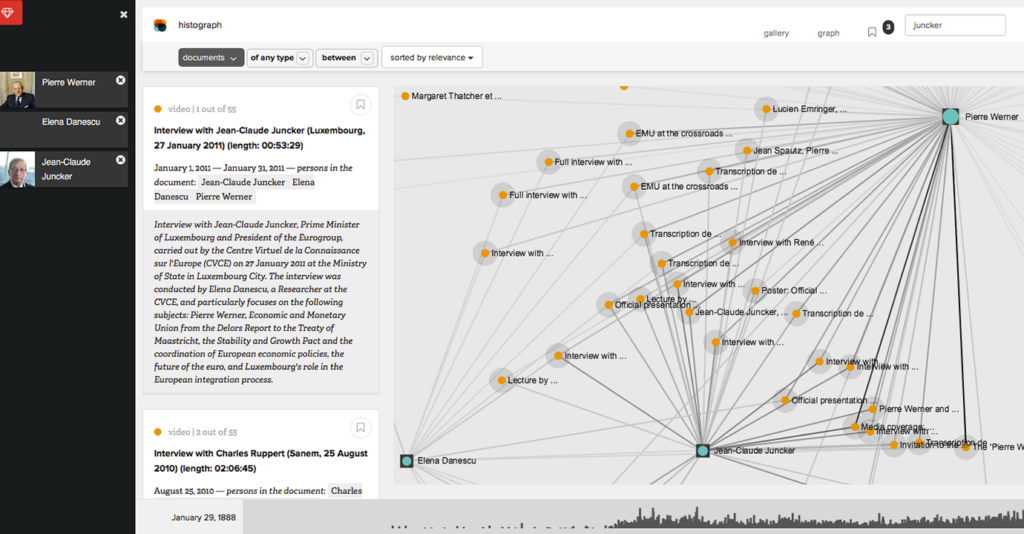
During my time at CVCE I acted as historical consultant during the development of histograph. Together with my colleagues Lars Wieneke and Daniele Guido we developled a tool for the graph-based exploration and crowd-based indexation of large-scale multimedia document collections. The tool was developed around a dataset of 17.000 documents linked by metadata and co-occurring linked named entities. A custom-built interface offers a close-reading perspective on the document, allows users to annotate named entities and to fix mistakes which occur during the automated entity detection and linking. A distant-reading graph visualisation reveals higher-level patterns in the data, offers path queries within the graph and the seamless switch between close- and distant reading views. Targeted at a user audience with low digital skills, histograph has the goal to make powerful automated processing and data visualisation accessible for lay audiences with low degrees in digital literacy.